Max Meldrum
Stockholm, Sweden.
Overview
2020 has been a strange year. The Covid-19 situation definitely impacted my motivation and productivity in the first half of the year. I am writing this post to give an update on the state of Arcon, but also to let other PhD students know that they are not alone if they have struggled this year.
Arcon is a streaming-first analytics engine built in Rust that is a part of the Continuous Deep Analytics project at KTH & RISE. Arcon is meant to be used either through the Arc programming language or directly through the Rust project.
Sections:
Threading Model
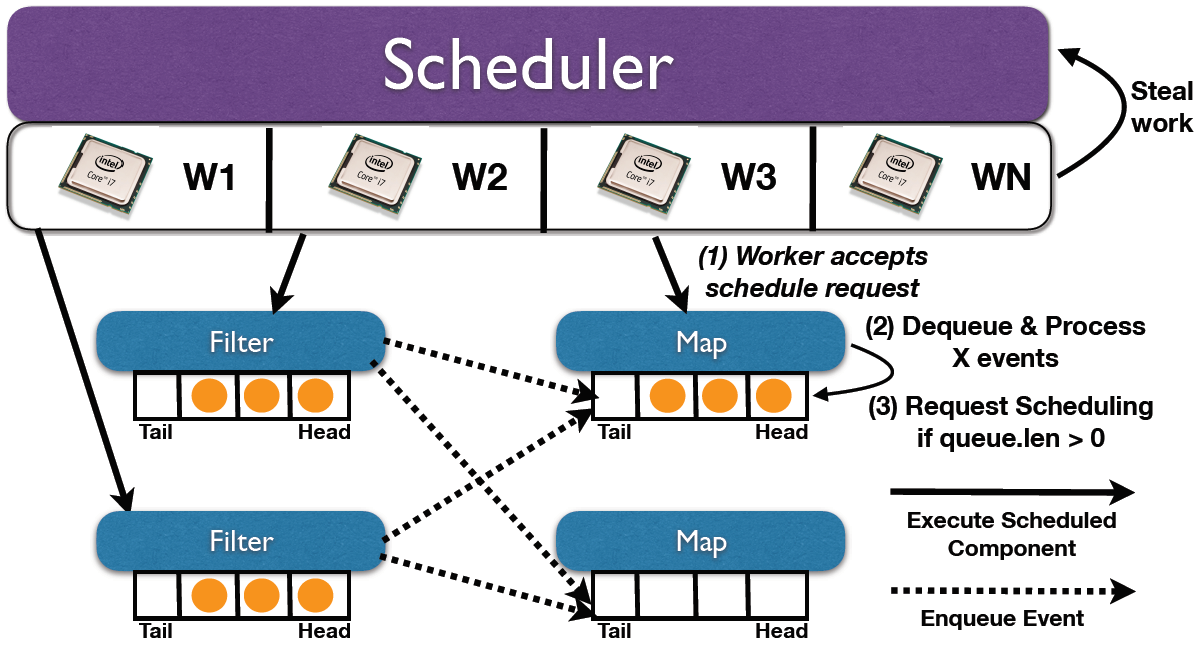
At the core of Arcon is the hybrid component + actor model framework Kompact, a sister project within the CDA research group. Arcon does not use dedicated threads, but rather relies on the work-stealing scheduler of Kompact to drive the execution of a streaming application.
A Node is a Kompact component that contains a user-defined Arcon Operator. An Operator may either be stateless or stateful. More on how state is handled is discussed in State Management. Ultimately, the goal of the Operator is to transform incoming data and send it downstream.
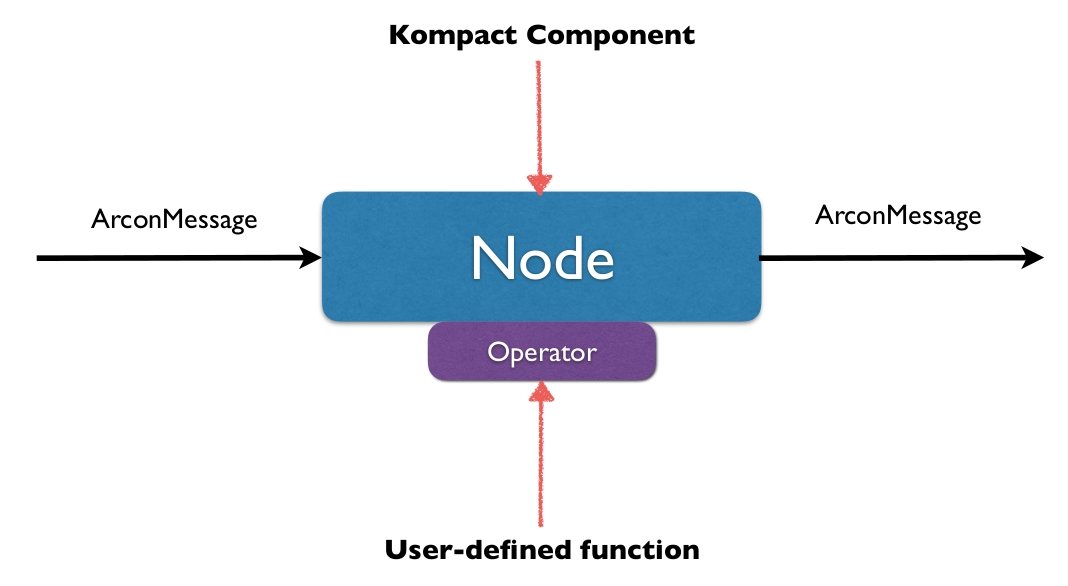
The image below shows how filter and map nodes are scheduled by Kompact.
State Management
A streaming pipeline without state would be pretty pointless. This section covers how Arcon approaches state.
Arcon makes a clear separation between active and historical state. Active state is maintained in in-memory indexes, while cold state is pushed down to a durable state backend. Streaming systems such as Apache Flink operate directly on the latter (e.g., RocksDB). This has several drawbacks. Typically the state backends are general-purpose key-value stores and are thus not specialised for streaming workloads. The state access pattern is not considered at all. Secondly, state calls have to serialise/deserialise for each operation.
Similarly to Apache Flink, Arcon operates on epoch boundaries. Therefore it is only necessary to persist modified state prior to running the epoch snapshotting protocol. Deserialisation in Protobuf (Arcon’s data format) compared to serialisation is costly. On my almighty laptop, it takes around 159 ns to serialise a “large” struct while it takes about 589 ns to deserialise it [Reference]. Arcon favours serialisation overhead over its deserialisation counterpart and thus state in Arcon is lazy and is only serialised if either the active state index is full and needs to evict data or if modified state needs to be persisted before executing a snapshot.
As implementing a custom state backend specialised for streaming would require a huge engineering effort, Arcon adds the Active State layer above existing state backends (See image below). The idea is to use the state backends for what they are good at, that is, storing state efficiently on disk and checkpointing.
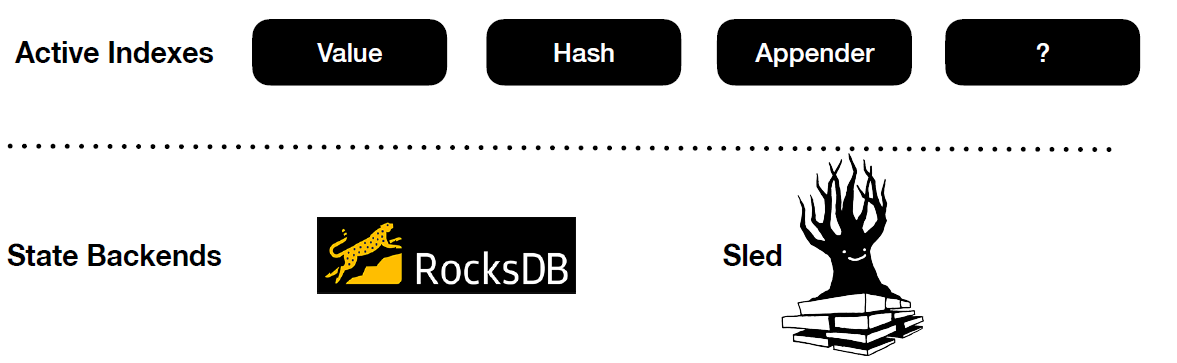
Arcon enables users to configure different state backends for different stages of the dataflow graph. For write-heavy workloads,
users may want to use RocksDB (LSM) as the state backend. Whereas for read-heavy workloads, Sled may be a better fit.
I want to thank Mikołaj Robakowski for his efforts in adding multiple state backends (e.g., RocksDB, Sled) implementations to Arcon.
Networking
Arcon relies on the networking implementation of Kompact. Arcon provides two in-flight serde modes, Unsafe and Reliable.
The former uses the very unsafe and fast Abomonation crate to serialise data, while the latter
depends on a more reliable but also slower option, Protobuf.
Luckily for Arcon, Kompact has seen some great performance improvements in its networking layer this year. This makes me excited to see how Arcon fares in a distributed execution.
Data format
Protobuf is the default data format in Arcon because it satisfies the following requirements:
- Schema Evoluton.
- Good space utilisation on disk.
- Decent serialisation/deserialisation cost
- Cross-language
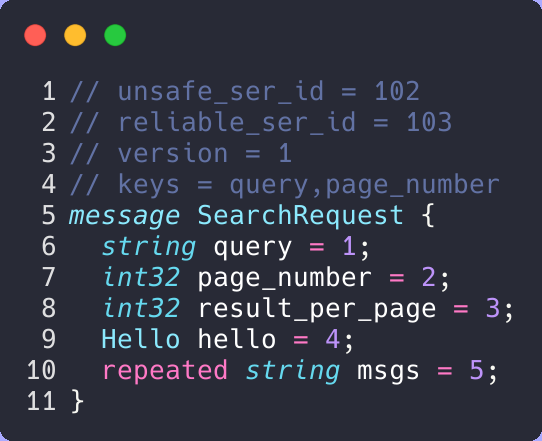
Users may declare Arcon data directly in Rust or generate them from .proto files. The proto definitions require some extra attributes to work in the Arcon runtime (see image below). A cool feature that Arcon has is that it will estimate the number of bytes used for the selected keys and choose an appropriate hasher (e.g., FxHash for small keys and XxHash for large keys).
Memory Management
Arcon comes with a custom allocator. Currently it is only used for event and network buffers, but the plan is to integrate it with active state indexes as well.
Another functionality on the TODO list is NUMA aware allocation.
Queryable State
This is a feature that is in the works. While Arcon is a streaming-first engine, it aims to provide capabilities to
run queries on top of a live pipeline. The plan is to use epoch alignments to keep a catalog of consistent state snapshots
that queries may subscribe to. Users will be able to combine state from different operators and possible different state backends in a single query.
I plan to dive further into this topic in a future post.
Summary
While a lot of core infrastructure is there, I would like to make Arcon usable by others than myself and a few others by the end of the year. To reach that goal, I have to tackle the following tasks:
- Finalise some internal design choices
- Create a user-friendly API
- Add documentation and examples
- Finish the Queryable State feature
Arcon is no solo effort. I want to thank colleagues and supervisors for their contributions and insights.
/ Max